abhi[dot]wadhwa[at] columbia [dot] edu
mentored research projects.
Deep Learning for High-Frequency Trading Signals
i tried RNNs, TCNs, and Transformers on order-book data to see which generalizes best for basic frontrunning-style HFT signals.
USC · Spring 2026
The hard part with order-book signals isn't fitting the data, it's that the patterns disappear fast, so i wanted to know which architecture actually generalizes. i worked out generalization bounds for each (Rademacher complexity): RNNs scale badly with how far back you look, TCNs are better, Transformers best. Then i generated fake order-book data with Hawkes processes and trained all three, and they ranked exactly how the theory said they would.
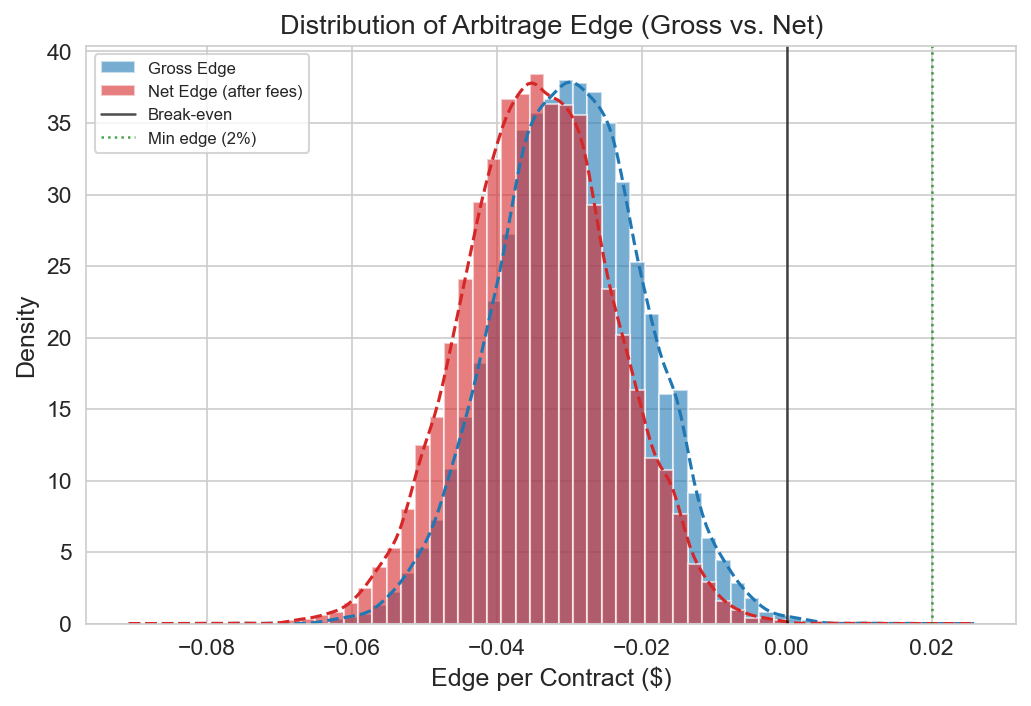
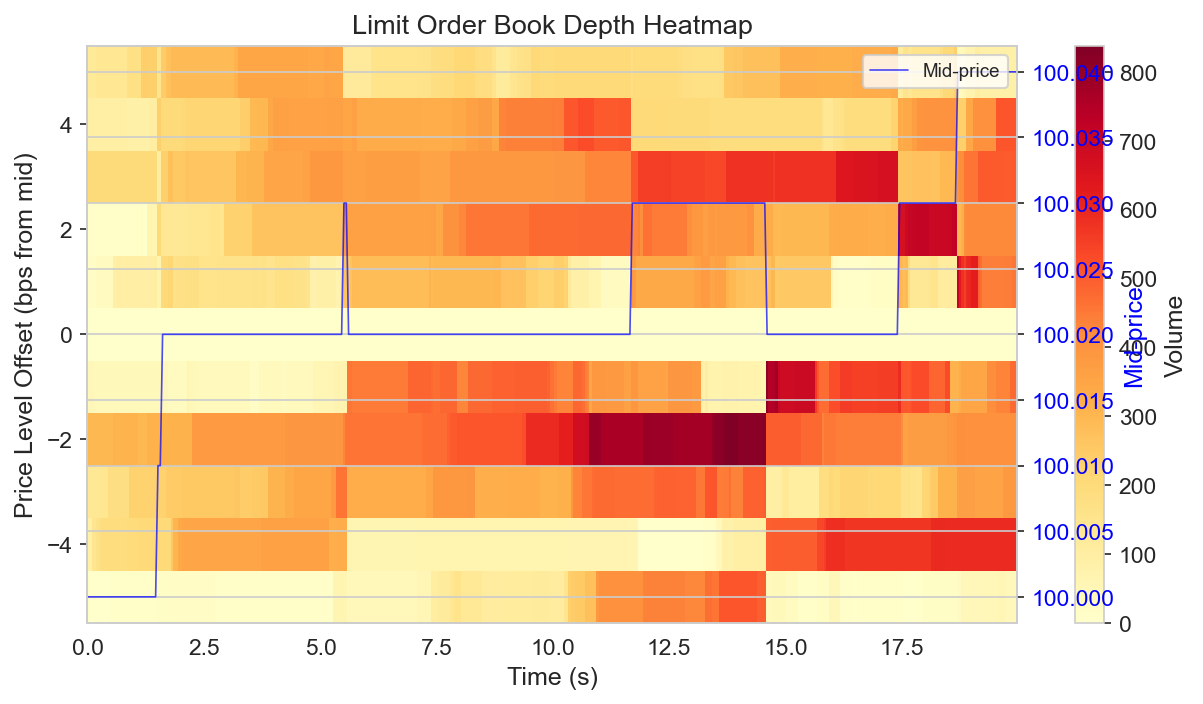
Cross-Platform Prediction Market Arbitrage
arbing the same event across Kalshi and Polymarket is an idea everyone's probably had, so i had gpt on the backend try to match contracts and see if it actually held up.
USC · Fall 2025
The catch is the two platforms name the same event differently and charge different fees, so the matching is the annoying part. i had gpt on the backend match equivalent contracts (~95% F1), then let an LLM agent and a plain rule-based agent both paper-trade for 90 days to see which actually made money. gpt was great at matching markets but kept fumbling the fee arithmetic, so it lost ($2,870 vs $4,230). Basically: let the model read the markets, let normal code do the math.
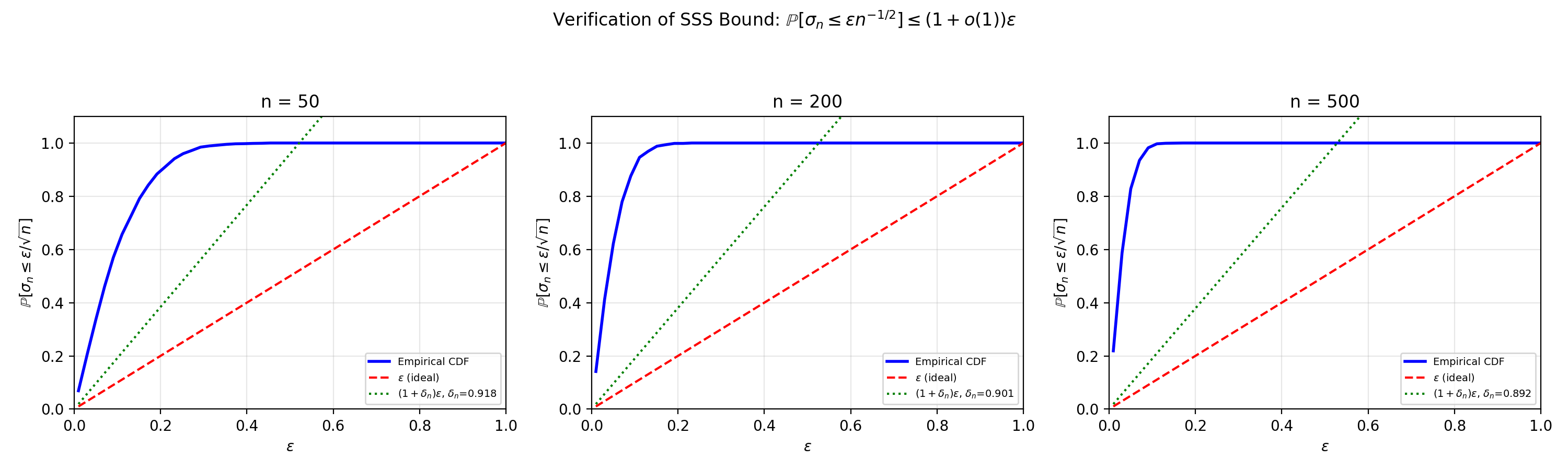
On the Resolution of the Spielman–Teng Conjecture
i read the 2024 proof that closed this old random-matrix conjecture and tried to re-explain it in a way i'd actually understand, then checked it in code.
USC · Fall 2025
The conjecture is basically about how small the smallest singular value of a random matrix can get, and it sat open for years until Sah, Sahasrabudhe, and Sawhney finally proved it in 2024. The proof is dense, so i went through it step by step and rewrote each piece (geometric reduction, truncation, Lindeberg exchange, rescaling) in plain language, then ran Monte Carlo simulations to check the bound shows up numerically. The reason i cared: that smallest singular value is exactly what sets a matrix's condition number, so the bound is really a statement that a random design matrix is well-conditioned on its own — which is the same thing explicit regularization (ridge's λI) is buying you when you add it by hand.
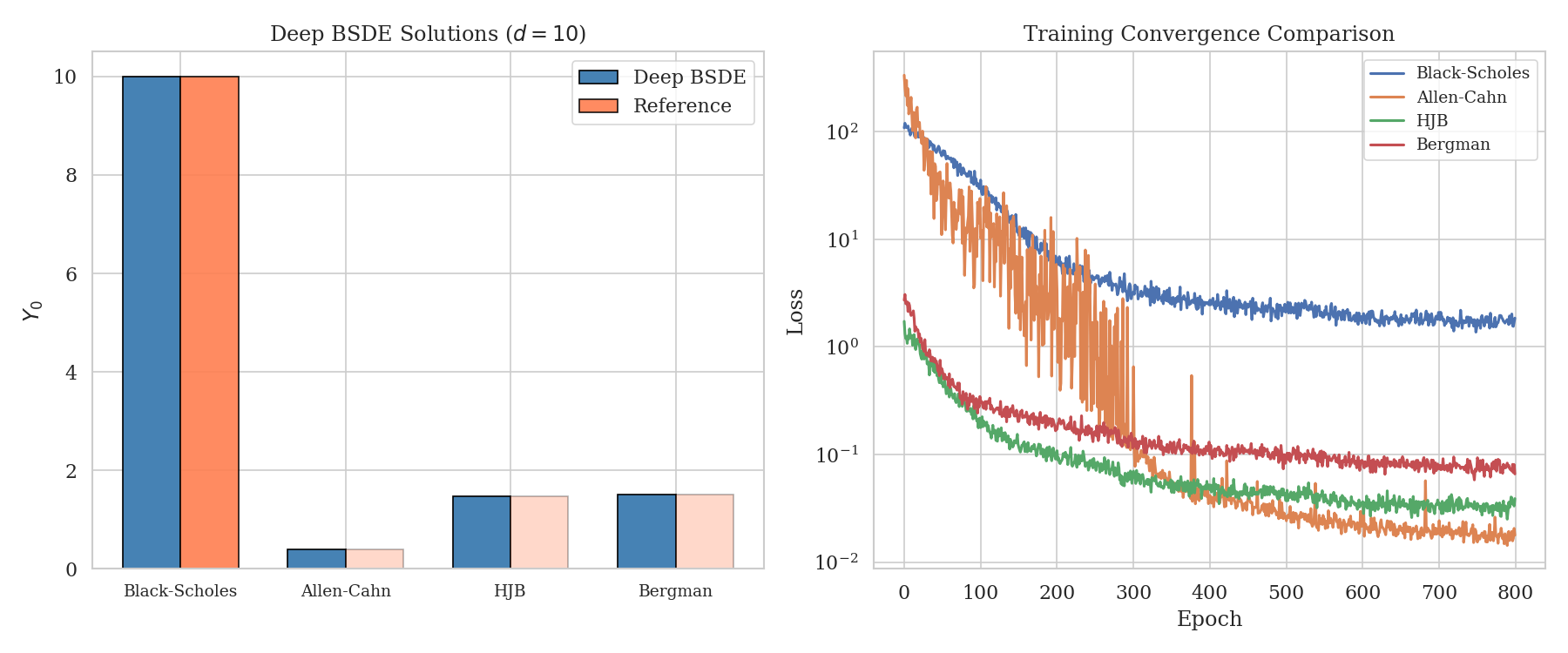
From Classical BSDEs to Deep Solvers
i learned how BSDEs are used to price derivatives and then coded up the old solvers vs a neural-net one to see when the classic methods break.
USC · Spring 2025
First i worked through why these equations show up in pricing at all (the nonlinear Feynman–Kac link between BSDEs and PDEs). Then i implemented three ways to actually solve them: least-squares Monte Carlo, finite differences, and the deep BSDE neural-net method. The classical solvers fall apart once you have a lot of dimensions, but the neural one still handles benchmark problems up to 50 dimensions, which was the whole point.
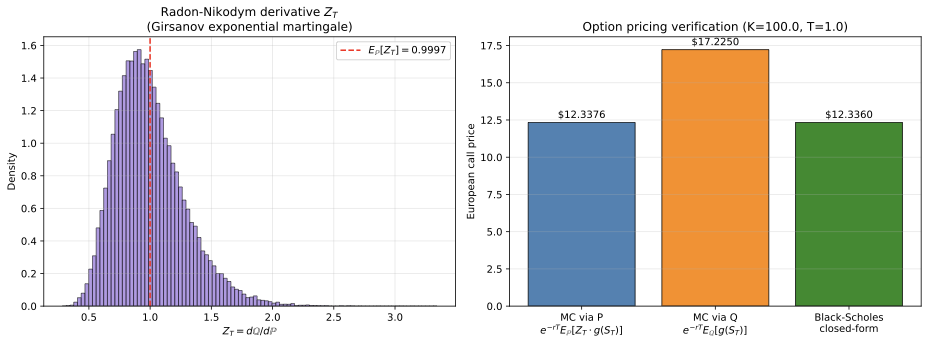
Measure Theory and Fine Properties of Functions
i taught myself the measure theory in Evans & Gariepy and then used it to actually derive Black–Scholes from scratch.
USC · Fall 2024
This started as me just trying to get through the hard measure-theory chapters in Evans & Gariepy (measures, Hausdorff dimension, Sobolev and BV functions, the coarea formula). To make it stick i pointed it at something concrete and re-derived Black–Scholes the measure-theoretic way, using Girsanov to change measure. i also wrote Python demos for the convergence and measure-change parts so they weren't just abstract.